
Medical History XML Parse - March 10, 2015
 It can be quite handy to
know ones medical history. Knowing if you have a history of heart disease,
cancer, or psychological issues can help one make good lifestyle choices (often
we don’t – but that’s beside the point). More importantly, your family medical
history can be an invaluable tool to helping your doctor assess and treat your
current and future health issues. A great tool that helps users document and
organize their medical history is the
My Family Health Portrait.
However, it would appear as though this tool only exports the resulting health
histories to Microsoft HealthVault and XML (using a data structuring/formatting
standard developed by www.hl7.org. I am assuming the
HealthVault is a proprietary format, which leaves us XML as the more versatile
format to work with in most cases.
It can be quite handy to
know ones medical history. Knowing if you have a history of heart disease,
cancer, or psychological issues can help one make good lifestyle choices (often
we don’t – but that’s beside the point). More importantly, your family medical
history can be an invaluable tool to helping your doctor assess and treat your
current and future health issues. A great tool that helps users document and
organize their medical history is the
My Family Health Portrait.
However, it would appear as though this tool only exports the resulting health
histories to Microsoft HealthVault and XML (using a data structuring/formatting
standard developed by www.hl7.org. I am assuming the
HealthVault is a proprietary format, which leaves us XML as the more versatile
format to work with in most cases.
The reason that this is an issue is as follows: most clinics are transitioning (or already have transitioned) away from paper-based file keeping, which is fantastic (for many reasons: greater accuracy, greater data integrity, greater data portability…). As one doctor told me, some of the database systems used require that documents be saved into the database in PDF format. However, this family history tool does NOT output any of the data to PDF format. Sure, you could print directly to PDF if your computer has the correct software installed – but many don’t, and I don’t think most doctors have the administrative permissions needed to install such tools if many of them would even know how. The other issue with this approach is either the information is displayed in a massive chart that could potentially be too wide for the page parameters of printers (again, there are workarounds, but many of those require the people using the tool to have a degree of technical savvy that is unreasonable to expect of most people, and it often requires a great deal of time – something physicians and their assistants generally do not have enough of), or it can be displayed in the information entry window, one person at a time, and then either printed to PDF or have a screenshot taken of it and paste that manually into a word processor. Both are time consuming, and neither is really a good option.
So, after looking at the XML file produced by this website, I realized that – in theory – it should be a relatively simple task to produce a program that could convert this into neatly formatted output with minimal need for user intervention. After giving it a bit of thought, my approach to the problem in broad strokes is as follows:
- Write the code necessary to parse the XML tags and store it as some sort of easily usable data in memory.
- Design an approach to transform the data in memory into formatted output.
- Turn that output into a PDF document.
- Wrap the program up in a clean GUI designed for ease of usability.
So far, I have pretty well got the first two items done. The first actually went a lot easier than I expected. This is probably due – at least in part – to learning about top-down programming and proper code documentation from my C++ professor. I first sketched out in very broad strokes everything the program needed to do, created stub functions for each of those things, and then broke each thing down into the steps that THEY needed to do, creating – in some cases – stub functions for those things. I also created a series of data structures that I could put together and use to store all of the tag data in a vector. I tracked things like tag name, tag function (opening or closing), tag id (in which the program assigns each tag an id number), parent id (in which a tags parent tag is identified), tag attributes and the value of those attributes. Frankly, I was not sure which bits of data I was going to need, and which I could do without as I had not sketched out the solution to formatting the data at this point.
Once I had that working, I created a simple print routine to dump all of the raw data to the screen to ensure that the functions and data structures were working as expected. Once that was sorted, then came the challenge of figuring out how to format the data. I spent a number of hours working on an approach in which I hard coded the rules for data formatting into the program itself, but this quickly grew cumbersome to keep track of, and was producing code that would be a nightmare to maintain. After giving it some thought, I decided to create a sort of configuration file that would contain all of the rules for formatting the data. Each tag is given an entry (some are NULL entries because I don’t really need to do anything with the tag), and then it is given a list of instructions for how to format the text. So, I created commands that had parameters to determine if they are executed when a tag is opening, closing, standalone or of any type. I created a basic conditional mechanism (called when, which is followed by a number telling it how many lines to skip if it evaluates to false), commands to create lines, commands to erase lines, commands to centre lines based on a given page width, and so on. Ultimately, this seems to work quite well, and has eliminated a lot of redundant code that would exist if I were to have tried hard-coding the text processing instructions (redundancy that would exist since many tags utilize instructions that all do similar things).
In my earlier attempt, I had been trying to output data directly to the screen. But I realized that it would be far simpler to write the data to a string – which can be easily manipulated – before printing it out. This was the other key to simplifying my approach to writing the formatting portion of the program. Once I could simply add to the front or end of a string, erase it, add tabs, and centre it when all of the content was present – it made the notion of using an independent set of formatting instructions feasible, and greatly increased the degree of control I had over the formatting (not being limited to the constraints imposed by using COUT to print directly to the console). Furthermore, I believe using a string to store a line of data as it is being formatted will make it much easier to modify the program to output the text to a PDF file. At this point, the program just prints out to the screen – which allows for fine tuning this portion of the program without the added complexity of handling a PDF file. In retrospect, it actually may not have been too problematic working out the PDF formatting issues before developing the data-formatting portion.
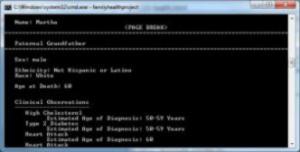
Anyway, for your viewing pleasure, I have created a file for the fictitious “Doe” family, and collected the formatted output from its XML is available here [link redacted].
So yeah, now I need to work on the PDF conversion portion – for which I plan to use the open source LibHaru library. While I probably could develop the code to write a PDF from scratch, it is sufficiently complex that this would be a truely time-consuming endeavor. Creating my rudimentary parsing system was plenty time consuming as it was (and it helped me appreciate why so many developers use pre-made libraries such as SDL and XML2: to cut down on the amount of work creating the functional overhead required to do an otherwise basic task). I’ll have to do some more tinkering with that particular library, go through some tutorials and maybe create some sort of wrapper to simplify the use of the bits I will be utilizing. Once that is complete, then I need to start learning about creating graphical applications for the Windows API so I can try to make this program as user friendly as possible.